

Every enterprise runs on documents. Invoices, purchase orders, insurance claims, loan applications, KYC packets, contracts, shipping manifests, and bank statements move through your business every day — and most of them still get read, keyed, and checked by people. That manual layer is slow, expensive, and error-prone, and it quietly caps how fast the rest of your automation can run.
Intelligent Document Processing (IDP) is the technology that removes that bottleneck, and in 2026 it is being rebuilt around large language models (LLMs). At KKRF Group, an experienced custom software development company, we design and build IDP pipelines that turn messy, real-world documents into structured, validated data your ERP, CRM, and downstream systems can trust. This guide explains what IDP is, how it works, what it costs, where it delivers ROI, and how to evaluate the right approach — written from the perspective of an engineering team that has shipped document-automation systems into production.
Key Takeaways
- IDP is OCR plus AI. It reads unstructured, variable-layout documents and outputs clean, structured, validated data — not just raw text.
- LLMs changed the economics. Generative models enable zero-shot extraction on document types the system has never seen, eliminating weeks of template configuration.
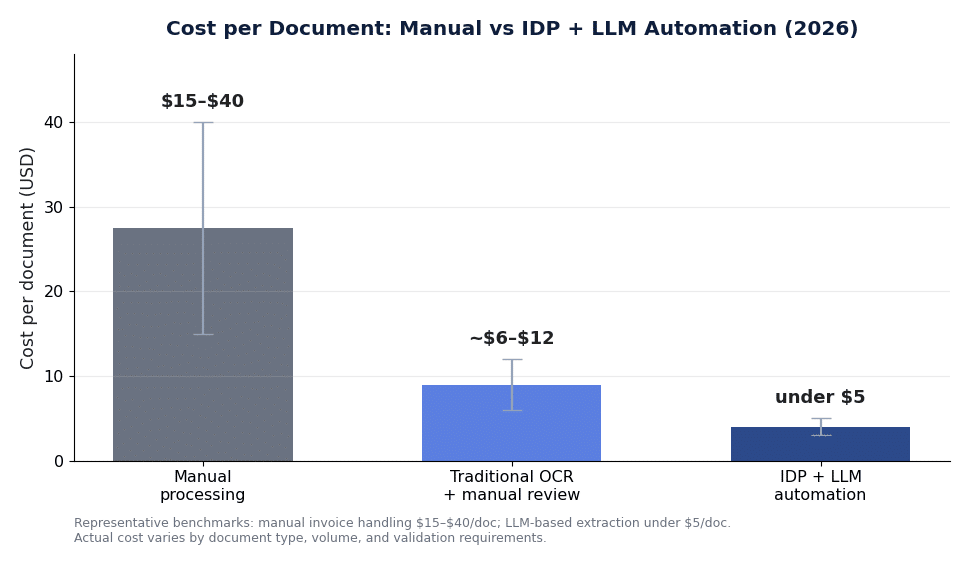
- Cost drops sharply. Manual document handling runs roughly $15–$40 per document; LLM-based extraction can bring that under $5.
- Accuracy is high but not magic. Modern IDP reaches 95–99% field-level accuracy; a human-in-the-loop step is still essential for high-stakes workflows.
- ROI is fast. Many enterprises recover their investment within 9–14 months, driven by 60–70% reductions in manual processing effort.
- Architecture and governance decide success. The winning differentiator in 2026 is orchestration, validation, and a self-improving feedback loop — not raw extraction alone.
What This Guide Covers
- What Intelligent Document Processing Is
- IDP vs OCR vs Document AI
- How an Enterprise IDP Pipeline Works
- What Intelligent Document Processing Costs
- High-Value Use Cases by Industry
- The ROI and Business Case
- Security, Compliance and Governance
- Common IDP Mistakes to Avoid
- How to Evaluate an IDP Partner
- The Future of Document Processing
- Frequently Asked Questions
Quick answer: Intelligent Document Processing (IDP) is an AI-powered method of capturing, understanding, and extracting data from business documents. It combines optical character recognition (OCR) with machine learning and large language models to read unstructured or semi-structured files — invoices, claims, contracts — and deliver clean, structured, validated data into your systems. In 2026, LLMs let IDP handle documents it has never seen before without template setup, at 95–99% field accuracy and a fraction of manual cost.
KKRF Group builds document-automation systems as custom engineering projects, not one-size-fits-all licenses. Our approach pairs enterprise-grade architecture with a security-first development process, so the pipeline fits your existing ERP, CRM, and compliance requirements rather than forcing your process to bend around a tool. The sections below reflect the decisions we work through with clients before a single line of extraction code is written.
What Intelligent Document Processing Actually Is
Intelligent Document Processing is the discipline of automatically capturing, classifying, extracting, and validating data from documents so that information can flow into business systems without manual keying. Traditional automation struggles here because business documents are rarely tidy. The same “invoice” arrives as a native PDF, a phone photo, a scanned fax, and an email attachment — each with a different layout, quality, and vocabulary.
Definition — Intelligent Document Processing (IDP): a technology stack that combines optical character recognition, computer vision, natural language processing, and machine learning (increasingly large language models) to convert unstructured and semi-structured documents into structured, machine-usable data with built-in validation.
The key word is understanding. Older tools could read characters; IDP interprets meaning. It knows that “Net 30,” “Payment due in 30 days,” and “Terms: 30 days” all describe the same field, and it can pull the correct total from an invoice even when the label, position, and currency change from vendor to vendor. That contextual reasoning is what large language models added to the category, and it is why IDP has moved from a niche capture tool to a core part of enterprise custom software strategy.
Definition — Zero-shot extraction: the ability of a generative model to extract fields from a document type it was never explicitly trained or templated for. This removes the traditional “configure a template per document layout” step that made older IDP projects slow to deploy.
IDP vs OCR vs Document AI: What Actually Changed
Buyers routinely confuse OCR, IDP, and the “Document AI” services sold by cloud hyperscalers. The distinction matters because it determines how much manual review your team will still be doing a year after go-live. OCR converts an image of text into machine-readable characters. IDP wraps OCR in AI that classifies the document, extracts specific fields, and validates them. The newest generation adds agentic behavior — the system decides which steps to run and can call external systems to check its own answers.
| Capability | Traditional OCR | IDP (OCR + AI/LLM) | Agentic Document Processing |
|---|---|---|---|
| Output | Raw text | Structured, labeled fields (JSON) | Structured data + actions taken |
| Handles variable layouts | Poorly | Yes, via ML/LLM understanding | Yes, adapts autonomously |
| Template setup | Not applicable | Little to none (zero-shot) | None |
| Field accuracy on real docs | Highly variable | 95–99% | 95–99% with self-checking |
| Validation | Manual downstream | Built-in rules + AI checks | Multi-step reasoning + tool calls |
| Best for | Clean, uniform scans | Mixed, real-world documents | Complex, multi-document workflows |
How an Enterprise IDP Pipeline Works
A production IDP system is not a single model — it is a pipeline of specialized stages, each with its own failure modes and controls. Understanding the stages helps you scope a project realistically and ask a vendor the right questions. The diagram below shows the flow we use as a starting architecture for most enterprise builds.
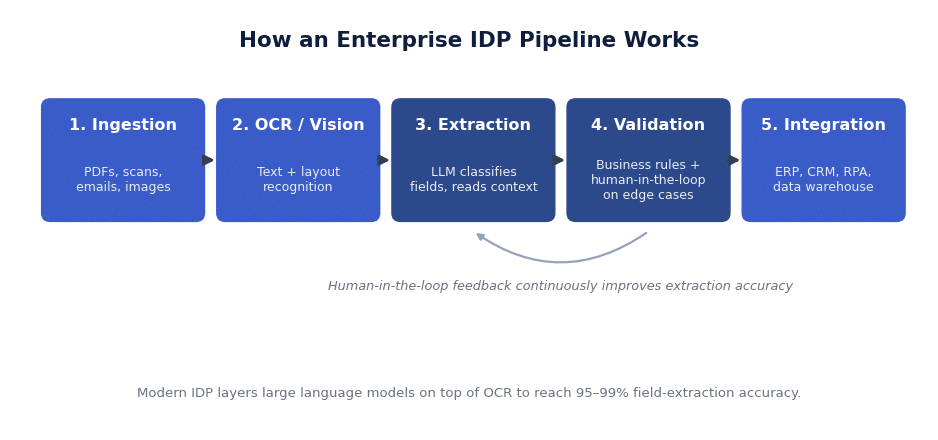
The pipeline typically runs through five stages:
- Ingestion and classification. Documents arrive from email, scanners, upload portals, or an API. The system detects the document type — invoice, claim, contract, ID — and routes it to the right extraction logic.
- OCR and vision. The raw image is converted to text while preserving layout, tables, checkboxes, and signatures. Quality checks flag low-resolution or skewed scans early.
- LLM extraction and classification. A large language model reads the text and layout together, identifies the fields you asked for, and normalizes them — dates to ISO format, amounts to a single currency, names to a canonical form.
- Validation and human-in-the-loop (HITL). Business rules, database lookups, and confidence scores decide whether a document passes automatically or is routed to a reviewer. Only genuine edge cases reach a person.
- Integration. Validated data is written to your ERP, CRM, data warehouse, or an RPA bot, and the outcome feeds back to improve future extractions.
Definition — Human-in-the-loop (HITL): a design where AI handles the bulk of documents automatically and routes only low-confidence or high-risk cases to a human reviewer. Their corrections are captured as training signal, so the system improves over time instead of making the same mistake repeatedly.
This is where many projects quietly succeed or fail. A pipeline that automates 70% of documents but has no clean way to handle the other 30% simply moves the bottleneck rather than removing it. The engineering value is in the orchestration, confidence thresholds, and feedback loop — the parts a demo rarely shows. For workflows that also reason across several related documents, teams increasingly connect these pipelines to AI agents and retrieval systems built on a vector database.
What Does Intelligent Document Processing Cost?
There are two cost conversations that matter: the per-document cost you are trying to reduce, and the project cost to build the system. On the first, the case for IDP is stark. Industry benchmarks put manual invoice handling at roughly $15 to $40 per document once you count labor, corrections, and exceptions, while LLM-based extraction can bring the marginal cost under $5 — and cloud models continue to push inference pricing down.
Project cost depends on document variety, volume, integration depth, and accuracy requirements. As a planning guide, the ranges we see for custom builds are:
| Project scope | Typical build range | What it usually includes |
|---|---|---|
| Pilot / single document type | $20,000–$60,000 | One workflow (e.g. invoices), core extraction, basic HITL review, one integration |
| Departmental deployment | $60,000–$250,000 | Several document types, validation rules, dashboards, ERP/CRM integration, monitoring |
| Enterprise platform | $400,000–$1M+ | Many document types, multi-system integration, governance, security, self-improvement loop |
Two costs surprise buyers. First, data preparation and integration — connecting to ERP, CRM, and internal databases — is usually a bigger line item than the AI itself. Second, inference is an ongoing operating cost: monthly model bills scale with document volume and can range from a few hundred to many thousands of dollars, so architecture choices that control token usage directly protect your margins.
Not sure whether your document workflow is a good IDP candidate? Our engineers can map your highest-volume document types to an ROI estimate and a realistic build scope. Tell us about your workflow and we will show you where automation pays off first.
Get a Technical Assessment →High-Value Use Cases by Industry
IDP earns its keep wherever a high volume of documents feeds a business decision. The strongest early candidates share three traits: repetitive processing, structured downstream systems, and a real cost to errors or delay. These are the workflows we most often automate first.
Finance and accounts payable
Invoice and purchase-order processing is the classic entry point: extract line items, match against POs and receipts, flag discrepancies, and post to the ERP. The same pattern extends to expense receipts, bank statements, and remittance advice. For finance teams already modernizing payments — including newer rails like stablecoin settlement — clean, structured document data is the foundation that automation depends on.
Insurance and healthcare
Claims processing, prior authorizations, and patient intake involve dense, variable forms where a missed field delays payment or care. IDP extracts and validates the data, routes exceptions to a specialist, and preserves an audit trail. Because this data is sensitive, the pipeline must enforce strict access control and data-handling rules from day one.
Lending, banking, and KYC
Loan applications, income verification, and Know Your Customer packets combine identity documents, financial statements, and forms. IDP accelerates onboarding while feeding structured data into risk models and compliance checks — turning a multi-day manual review into hours.
Logistics and legal
Bills of lading, proof-of-delivery slips, and customs paperwork drive supply-chain systems, while contract review benefits from extracting clauses, dates, and obligations. In both cases IDP replaces error-prone re-keying and surfaces the specific data points a downstream process actually needs.
The ROI and Business Case
The business case for IDP rests on three levers: labor reduction, error reduction, and speed. On labor, enterprises commonly report 60–70% reductions in manual processing effort as staff shift from keying data to handling exceptions. On accuracy, validated extraction reduces the costly downstream errors — misposted invoices, rejected claims — that manual entry produces. On speed, cycle times fall from days to minutes, which improves cash flow and customer experience.
Put together, these translate into fast payback. Many organizations recover their investment within 9 to 14 months, and the returns compound as more document types move onto the same platform. The IDP market itself reflects this pull: analysts value it in the range of $10–11 billion in 2025 and project growth of roughly 26% per year through the early 2030s, with North America accounting for close to half of global spend.
- Baseline your current cost. Volume × fully-loaded cost per document × error/rework rate.
- Model the automated state. Expected automation rate, per-document inference cost, and the residual HITL effort.
- Account for build and run. One-time build plus ongoing inference, monitoring, and model maintenance.
- Track the second-order gains. Faster cycle times, fewer penalties, and staff redeployed to higher-value work.
Security, Compliance and Data Governance
Because IDP touches financial, personal, and contractual data, security is not a feature bolted on at the end — it is an architectural constraint from the first design session. The core questions are where documents are stored, which model sees the data, how long anything is retained, and who can access extracted fields.
A security-first IDP build typically enforces encryption in transit and at rest, role-based access control, PII detection and redaction, and detailed audit logging. For regulated industries, data residency and the choice between hosted API models and self-hosted or private-cloud models becomes a central decision — one that trades convenience against control. Aligning the design with a recognized framework such as the NIST AI Risk Management Framework gives stakeholders a shared language for evaluating and documenting these risks.
Governance also means planning for model behavior. LLMs can occasionally produce confident but wrong extractions, so confidence thresholds, validation rules, and human review on high-stakes fields are what keep an automated pipeline trustworthy. Cloud providers publish detailed guidance on building these controls, including AWS and Microsoft’s Azure AI Document Intelligence documentation.
Common IDP Mistakes to Avoid
Most IDP disappointments trace back to a handful of avoidable decisions. Knowing them in advance is the difference between a pilot that stalls and a platform that scales.
- Chasing 100% automation. Designing as if every document can be fully automated ignores the edge cases that matter most. A well-designed HITL path is a feature, not a failure.
- Starting with the hardest document. Teams often pick their messiest, highest-stakes document first. Prove value on a high-volume, well-understood type, then expand.
- Treating accuracy as the only metric. Straight-through-processing rate, exception-handling time, and cost per document tell you more about business impact than a headline accuracy number.
- Underinvesting in integration. Extraction is worthless if the data cannot flow cleanly into your systems. Integration and data mapping deserve real engineering time.
- Ignoring the feedback loop. Without capturing reviewer corrections, the system never improves and quietly decays as documents drift.
- No monitoring after go-live. Vendors change formats and models update. Production monitoring catches accuracy regressions before they reach your books.
How to Evaluate an IDP Development Partner
Whether you build in-house, buy a platform, or engage an engineering partner, the evaluation comes down to how well the solution fits your documents, your systems, and your risk profile. A capable partner should be comfortable being measured against a simple framework.
- Fit to your documents. Can they demonstrate accuracy on your real, messy samples — not a polished demo set?
- Integration depth. Do they have concrete experience wiring extraction into ERP, CRM, and data platforms like the ones you run?
- Orchestration and HITL. How do they handle low-confidence cases, and how does the system learn from corrections?
- Security and compliance. Can they meet your data-residency, access-control, and audit requirements, including self-hosted model options?
- Total cost of ownership. Do they model inference and maintenance, not just the build, and design to control ongoing token spend?
- Transparency. Do you get a clear development process, source-code ownership, and honest discussion of limitations?
This is the lens we apply to our own work. As a technology partner, KKRF Group builds IDP as bespoke engineering: we validate accuracy against your documents, design the integration and governance around your existing stack, and stay accountable for the pipeline’s performance in production. For organizations modernizing older document workflows, IDP often pairs naturally with a broader legacy modernization effort rather than sitting as an isolated tool.
The Future of Intelligent Document Processing
The near-term trajectory is clear: extraction accuracy on standard documents is becoming a commodity, so competitive advantage is shifting to what happens around extraction. Expect three moves to define 2026 and beyond. First, agentic document processing, where systems plan multi-step workflows and call external tools to verify their own outputs. Second, multimodal understanding, where models reason over text, tables, images, and signatures together. Third, self-improving pipelines that turn every human correction into measurable accuracy gains.
The practical implication for buyers is to invest in architecture that can absorb these advances — modular pipelines, clean data contracts, and a feedback loop — rather than betting on a single model that will inevitably be superseded. Built that way, an IDP platform becomes a durable asset that grows more capable as the underlying models improve.
Planning an IDP build and want a second opinion on architecture, model choice, and governance before you commit? Our engineering team can review your approach and flag the decisions that most affect cost and accuracy. Bring us your document workflow and we will pressure-test the plan with you.
Request an Architecture Review →Frequently Asked Questions
What is the difference between OCR and Intelligent Document Processing?
OCR converts an image of text into machine-readable characters. Intelligent Document Processing wraps OCR in AI that classifies the document, extracts the specific fields you need, validates them against rules or databases, and outputs clean structured data. In short, OCR gives you text while IDP gives you trustworthy, ready-to-use data.
How accurate is Intelligent Document Processing?
Modern IDP systems typically achieve 95–99% field-level accuracy because they understand context and validate results, compared with the highly variable output of OCR alone. For workflows that require near-perfect accuracy, a human-in-the-loop review step handles the small share of low-confidence cases and feeds corrections back to improve the model.
How much does it cost to build an IDP solution?
A single-workflow pilot commonly runs $20,000–$60,000, a departmental deployment $60,000–$250,000, and an enterprise platform $400,000 and up, depending on document variety, integration depth, and accuracy requirements. Ongoing inference and maintenance are separate operating costs that scale with document volume.
What documents can IDP handle?
IDP is designed for unstructured and semi-structured documents such as invoices, purchase orders, insurance claims, loan applications, KYC packets, contracts, bills of lading, and ID documents — including scans, photos, and native PDFs with varying layouts. With large language models, it can often process new document types without per-template configuration.
Is Intelligent Document Processing secure for sensitive data?
It can be, when security is designed in from the start. A sound IDP build uses encryption in transit and at rest, role-based access control, PII detection and redaction, and audit logging, and for regulated data it may use self-hosted or private-cloud models to keep information in your environment. Aligning the design with a framework like the NIST AI Risk Management Framework helps document and manage the risk.
How long does it take to deploy IDP?
A focused pilot on one document type can often go live in a few weeks, while a broader enterprise platform spanning multiple document types and integrations usually takes a few months. Because LLM-based extraction reduces template setup, timelines are shorter than earlier-generation IDP projects — the integration and validation work is typically the longer pole.
Ready to turn your document backlog into structured, automated data? KKRF Group designs and builds enterprise IDP pipelines — from a single high-volume workflow to a full document-automation platform — with the security and integration your systems demand. Talk to our engineering team to scope your project.
Discuss Your Project →







