

Choosing the right vector database has quietly become one of the highest-leverage architecture decisions in enterprise AI. This vector database comparison cuts through the marketing to show how Pinecone, Weaviate, Qdrant, and pgvector actually behave under a production retrieval-augmented generation (RAG) system. Pick wrong and the cost shows up later as runaway cloud bills, sluggish answers, or a painful rebuild six months in.
Vector search is no longer a niche concern. Every RAG assistant, semantic search feature, recommendation engine, and AI agent depends on a store that can hold millions of embeddings and return the closest matches in milliseconds. Below we compare the leading options on architecture, cost, security, and real-world fit, so an engineering leader can decide with evidence instead of hype.
Key Takeaways
- pgvector is often the most practical starting point. If your data already lives in PostgreSQL, adding vector search there avoids running a second system entirely.
- Pinecone is the fastest path to managed scale. It trades a higher price for near-zero operational burden and billions of vectors at sub-100ms latency.
- Qdrant, Weaviate, and Milvus each lead a niche. Qdrant for open-source speed and filtering, Weaviate for native hybrid search and multi-tenancy, Milvus for billion-scale workloads.
- Managed costs 1.5x to 3x more than self-hosted around the 10-million-vector mark, but removes provisioning, scaling, and upgrade work.
- For RAG, retrieval quality beats raw speed. Metadata filtering, update and delete behavior, hybrid search, and predictable latency matter more than a benchmark leaderboard.
- There is no universal winner. The right choice depends on data scale, team maturity, compliance needs, and how much you already invest in Postgres.
In This Article
- What Is a Vector Database?
- How RAG Reshapes the Requirements
- The Main Contenders in 2026
- Vector Database Comparison Table
- Pricing at Enterprise Scale
- Managed vs Self-Hosted
- Security, Compliance & Multi-Tenancy
- How to Evaluate a Vector Database
- Common Mistakes to Avoid
- ROI and the Business Case
- Future Trends for 2026
- Decision Framework
- Choosing an Implementation Partner
Quick Answer: Which Vector Database Should You Choose?
For most enterprises building RAG in 2026, start with pgvector if your data already sits in PostgreSQL and you are under roughly 10 to 50 million vectors. Move to Qdrant or Weaviate when you need advanced filtering, hybrid search, or higher throughput. Choose Pinecone when you want a fully managed service that scales to billions of vectors without an infrastructure team, and reach for Milvus only at extreme, billion-vector scale. Match the database to your workload, not to whichever brand is loudest.
KKRF Tech is a leading AI and ML integration partner that has architected retrieval pipelines and vector search backends for RAG assistants, semantic search, and AI agents across several industries. We keep seeing the same pattern: teams over-provision a managed vector database early, then spend months untangling cost and latency. The guidance here reflects those production lessons, not vendor datasheets.
What Is a Vector Database?
A vector database is a system built to store, index, and search high-dimensional vectors — the numerical embeddings that represent the meaning of text, images, audio, or code. Instead of matching exact keywords, it finds items whose vectors are closest in space, which is exactly what makes semantic search and RAG possible.
Embeddings are dense numerical arrays produced by a machine-learning model, arranged so that similar concepts land near each other in vector space. A sentence about invoices and one about billing sit close together even when they share no words.
Approximate nearest neighbor (ANN) search is the technique vector databases use to find the closest vectors quickly. Rather than comparing a query against every stored vector, ANN algorithms trade a sliver of accuracy for enormous speed gains.
HNSW (Hierarchical Navigable Small World) is the most widely used ANN index. It builds a layered graph of vectors that lets the engine hop toward the nearest neighbors in near-logarithmic time, balancing recall and latency through tunable parameters such as ef_construction and M.
A traditional relational database can technically store vectors, but scanning millions of them by brute force is far too slow for interactive applications. Purpose-built vector engines — and Postgres via the pgvector extension — add specialized indexes so a query over tens of millions of embeddings returns in milliseconds rather than seconds.
How RAG Reshapes the Requirements
RAG changes the priorities. In a retrieval-augmented generation system, the vector database is the retrieval layer that grounds an LLM in your private data, so its accuracy and latency directly shape answer quality and user trust. A slightly faster benchmark means little if the retriever surfaces the wrong passages.
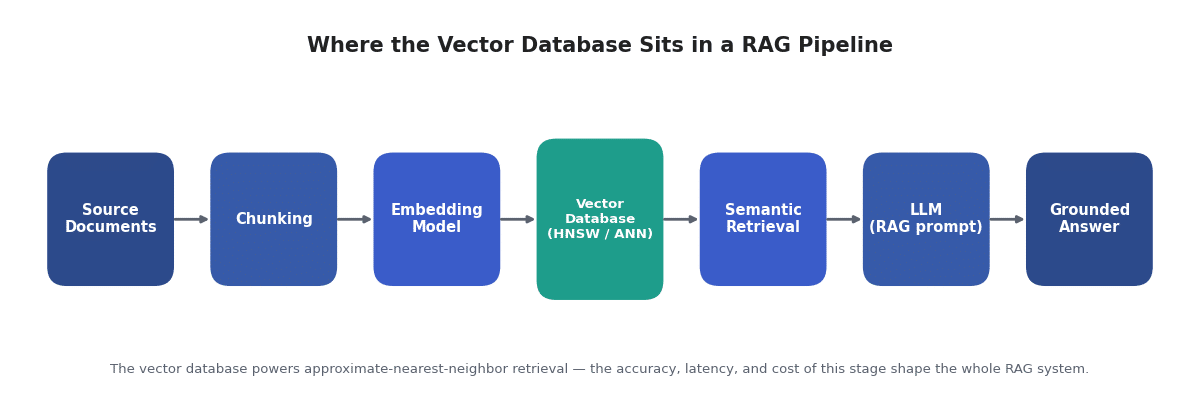
Because retrieval feeds a language model, five capabilities matter more in RAG than in generic vector search:
- Metadata filtering: restrict results by tenant, permission, document type, or recency so users never see data they should not.
- Update and delete behavior: enterprise documents change constantly; stale or orphaned vectors produce confidently wrong answers.
- Hybrid search: combining keyword (BM25) and semantic scoring recovers exact matches like part numbers or error codes that pure vectors miss.
- Provenance: returning source IDs and metadata enables citations, which are non-negotiable for enterprise trust.
- Predictable latency under load: tail latency, not average latency, determines how the assistant feels during peak traffic.
In short: for RAG, judge a vector database on filtering, freshness, and hybrid retrieval quality first, and on raw throughput second.
The Main Contenders in 2026
Five engines dominate serious enterprise RAG shortlists in 2026. Each is introduced below with the context that matters for a decision.
Pinecone is a fully managed, cloud-native vector database. It handles provisioning, scaling, and managed reranking for you, scales to billions of vectors at sub-100ms latency, and is the least operationally demanding option — at a premium price.
Weaviate is an open-source vector database available self-hosted or as Weaviate Cloud. It ships native hybrid search, pluggable embedding modules, and strong multi-tenancy, which makes it a natural fit for multi-tenant SaaS platforms that isolate many customers.
Qdrant is an open-source, Rust-based vector database known for speed and advanced payload filtering. Independent benchmarks place it among the fastest open-source engines, and it runs comfortably self-hosted or on Qdrant Cloud.
pgvector is an open-source extension that adds vector columns and ANN indexing to PostgreSQL. It lets teams store embeddings beside relational data and query both with plain SQL, avoiding a separate system entirely — the reason it has become many teams’ default.
Milvus and Chroma round out the field. Milvus is a distributed vector database engineered for billion-scale similarity search with multiple index types, while Chroma is a lightweight store popular for prototyping and local development.
Vector Database Comparison Table
This vector database comparison summarizes how the leading engines differ across deployment model, indexing, hybrid search, and target scale. Use it to build a shortlist, then validate the two or three finalists against your own data.
| Database | Deployment | Best For | Hybrid Search | Typical Scale Sweet Spot |
|---|---|---|---|---|
| Pinecone | Fully managed (SaaS) | Hands-off managed scale | Yes (managed) | Millions to billions |
| Weaviate | Open source or managed | Hybrid search & multi-tenant SaaS | Native | Millions to hundreds of millions |
| Qdrant | Open source or managed | Speed & rich filtering | Yes | Millions to hundreds of millions |
| pgvector | Postgres extension | Teams already on PostgreSQL | Via SQL + full-text | Thousands to tens of millions |
| Milvus | Open source / distributed | Billion-scale workloads | Yes | Hundreds of millions to billions |
No row is the “winner.” The table narrows options by fit: if you are already on Postgres, pgvector earns the first look; if you need turnkey scale, Pinecone leads; if filtering and speed dominate, Qdrant and Weaviate compete closely.
Not sure which of these engines fits your data volume, latency targets, and budget? KKRF Tech can benchmark your shortlist against your own embeddings before you commit to a platform. Tell us about your RAG project and we will map the real trade-offs for you.
Get a Vector Database Assessment →Vector Database Pricing at Enterprise Scale
Vector database pricing is where teams get surprised. Entry tiers look cheap, but real cost scales with vector count, dimensions, query volume, and replication — and managed services typically run 1.5x to 3x more than self-hosted at the same scale. The chart below shows directional monthly cost for a mid-size RAG workload of roughly 10 million vectors.
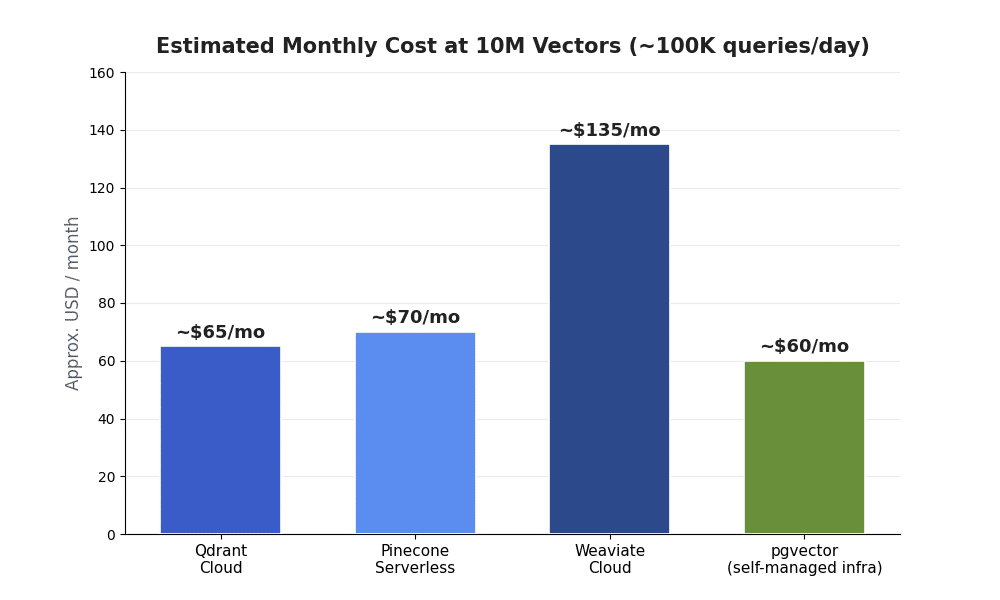
| Provider | Entry price | ~Cost at 10M vectors | Storage rate |
|---|---|---|---|
| Qdrant Cloud | from ~$25/mo | ~$65/mo | ~$0.28 /GB/mo |
| Pinecone | pay-as-you-go; Enterprise from ~$500/mo | ~$70/mo (serverless) | ~$0.30 /GB/mo |
| Weaviate Cloud | from ~$45/mo (Plus ~$280/mo with SLA) | ~$135/mo | ~$0.095 /GB/mo |
| pgvector | free (open source) | infrastructure only (~$60/mo est.) | your Postgres storage |
Two lessons hold across providers. First, storage rate and query volume, not the sticker price, drive the bill at scale — Weaviate’s lower per-GB rate can flip the ranking for storage-heavy corpora. Second, self-hosting pgvector or Qdrant shifts spend from vendor fees to engineering time, so it only pays off when you have the operational maturity to run it well. See Pinecone’s own pricing documentation for a current managed estimate.
Managed vs Self-Hosted: The Core Trade-off
The managed-versus-self-hosted decision matters more than the brand. Managed services absorb provisioning, scaling, and upgrades so your team can focus on the application; self-hosted options give you control and lower hosting fees in exchange for real operational work.
| Factor | Managed (Pinecone, cloud tiers) | Self-hosted (pgvector, Qdrant, Milvus OSS) |
|---|---|---|
| Time to production | Fastest | Slower — setup and tuning required |
| Ongoing cost | Higher, predictable | Lower fees, higher engineering time |
| Ops burden | Vendor-handled | Your team owns uptime and scaling |
| Control & data residency | Limited by vendor regions | Full control, any environment |
| Tuning ceiling | Abstracted away | Full access to HNSW and index params |
A pragmatic rule: choose managed when speed to market and small teams matter, and self-hosted when data residency, cost at very large scale, or deep tuning control are decisive. Open engines like pgvector and Qdrant publish the internals you will need to run them well. If you lack a platform team, our cloud consulting group can operate the stack for you.
Security, Compliance & Multi-Tenancy
Security is not optional once embeddings contain business data. Treat the vector database as a system of record: it holds fragments of your source documents and, in RAG, is one query away from exposing them to the wrong user.
- Encryption: require encryption at rest and in transit; for regulated data, confirm bring-your-own-key support.
- Access control: role-based access and per-collection permissions prevent a single leaked key from exposing every tenant.
- Data residency: GDPR, HIPAA, and SOC 2 obligations often dictate region and self-hosting; verify the provider’s certifications and available regions.
- Tenant isolation: in multi-tenant SaaS, choose namespace, collection, or database-per-tenant isolation deliberately — metadata filtering alone is not a security boundary.
- PII in embeddings: embeddings can leak sensitive attributes; redact or tokenize before indexing where required.
- Network isolation: prefer VPC peering or private endpoints over public internet access for production.
Summary: pick isolation and residency controls to match your compliance regime before you optimize for latency or cost.
How to Evaluate a Vector Database
Evaluate with your own data, not a vendor demo. Follow a structured process so the finalist earns its place on evidence.
- Define the workload: vector count, embedding dimensions, expected queries per second, and growth over 12 months.
- List hard constraints: compliance, data residency, budget ceiling, and existing infrastructure such as Postgres.
- Shortlist two or three engines from the comparison table that satisfy those constraints.
- Load a representative sample — at least a few million real embeddings, not toy data.
- Measure recall and latency together: tune the index, then record p95 and p99 latency at target recall.
- Test filtering and updates: run metadata-filtered queries and confirm deletes and re-indexing behave correctly.
- Model total cost: project cost at 12- and 24-month data volumes, including engineering time for self-hosted options.
- Run a limited pilot behind a feature flag before committing the whole system.
Common Mistakes to Avoid
Most vector database regrets trace back to a handful of avoidable errors.
- Choosing on benchmarks alone: synthetic speed tests ignore filtering, freshness, and your real recall needs.
- Over-provisioning managed tiers early: paying for billions of vectors of capacity while serving thousands.
- Ignoring update and delete costs: re-indexing churn can dominate cost in dynamic corpora.
- Skipping hybrid search: pure semantic retrieval misses exact identifiers users expect to match.
- Treating metadata filters as security: a filter is a convenience, not an isolation boundary.
- Adding a new system when Postgres would do: introducing a separate database when pgvector already covers the scale you need.
- No evaluation harness: shipping retrieval with no way to measure whether answer quality improves or regresses.
ROI and the Business Case
The business case for getting this right is concrete. A well-chosen vector database lowers infrastructure spend, speeds up answers, and — most importantly — improves retrieval quality, which is the single biggest driver of whether a RAG product is trusted and adopted.
On the cost side, matching the database to workload avoids the classic 2x to 4x overspend that comes from defaulting to a premium managed tier. On the value side, better retrieval reduces hallucinations and support escalations, shortens research time for knowledge workers, and raises the accuracy of AI agents acting on internal data.
Frame ROI as three levers: reduced infrastructure cost, reduced engineering rework from choosing correctly the first time, and increased adoption from higher answer quality. A short, data-driven evaluation up front is inexpensive insurance against an expensive migration later.
Future Trends for 2026
The vector database category is consolidating and maturing rather than fragmenting. A few directions are worth planning for.
- Postgres as the default entry point: pgvector momentum keeps pulling first-time teams toward one system for relational and vector data.
- Hybrid and multi-vector search as table stakes: keyword-plus-semantic and multi-vector retrieval are moving from differentiators to baseline expectations.
- Quantization and cost efficiency: scalar and binary quantization cut memory and storage cost dramatically, reshaping pricing math.
- Tighter agent integration: vector stores are becoming long-term memory for AI agents, raising the bar for update speed and filtering.
- Convergence of features: the gap between engines is narrowing, so operational fit and cost increasingly matter more than any single feature.
Decision Framework: Which Fits Your Use Case
Use this framework to convert the comparison into a decision. Start from your constraints, then match to the engine whose strengths line up.
- Choose pgvector when your data is already in PostgreSQL, you are under tens of millions of vectors, and you value one system over the last few points of performance.
- Choose Qdrant when you need fast, heavily filtered search and are comfortable self-hosting or using its managed cloud.
- Choose Weaviate when native hybrid search and strong multi-tenancy for a SaaS product are priorities.
- Choose Pinecone when you want fully managed scale with minimal operations and can budget for it.
- Choose Milvus when you genuinely operate at billion-vector scale with a team to run distributed infrastructure.
When not to add a dedicated vector database: if you are prototyping, serving under a few million vectors, or already run Postgres, a separate system usually adds cost and operational surface for little gain. As an experienced AI and ML integration partner, KKRF Tech routinely helps teams start with pgvector and graduate to a specialized engine only when measured scale or feature needs justify it — sequencing the vector database decision to the actual roadmap rather than to hype.
Choosing an Implementation Partner
The database is one piece; the pipeline around it decides success. When evaluating an implementation partner for RAG and vector search, look for evidence they can own the whole retrieval problem, not just stand up a database.
- Demonstrated RAG and embedding-pipeline experience, with a retrieval evaluation methodology.
- Fluency across both managed and self-hosted engines, so the recommendation is unbiased.
- Security and compliance practices that match your regulatory environment.
- A cost model that projects spend at future scale, not just today.
- Clear handoff, documentation, and the option to operate the stack long term.
If that describes the help you need, our team can design, benchmark, and ship the full retrieval layer.
A production RAG system is far more than a database choice — chunking, embeddings, retrieval quality, and evaluation all decide whether answers are trustworthy. As a leading AI and ML integration partner, KKRF Tech designs and ships the full pipeline. See how we build AI-powered products.
Talk to Our RAG Engineers →What is the best vector database for RAG in 2026?
There is no single best vector database for RAG. pgvector is the best default when your data already lives in PostgreSQL and you are under tens of millions of vectors. Pinecone is best for hands-off managed scale, Qdrant and Weaviate for advanced filtering and hybrid search, and Milvus for billion-scale workloads.
Is pgvector good enough for production RAG?
For many applications, yes. pgvector adds ANN vector search directly to PostgreSQL and comfortably handles thousands to tens of millions of vectors. It is often the most practical production choice because it keeps embeddings beside your relational data in one system. Move to a dedicated engine when you outgrow that scale or need advanced filtering and hybrid search.
How much does a vector database cost at enterprise scale?
Directionally, at around 10 million vectors a managed service runs roughly $65 to $135 per month, while self-hosted pgvector or Qdrant mainly costs the underlying infrastructure. Managed offerings typically cost 1.5x to 3x more than self-hosted at the same scale, and real bills depend on vector count, dimensions, query volume, and storage.
Should an enterprise choose a managed or self-hosted vector database?
Choose managed when speed to market matters and your team is small, since the vendor handles scaling and upgrades. Choose self-hosted when data residency, cost at very large scale, or deep index tuning are decisive and you have the operational maturity to run it. The trade-off is vendor fees versus engineering time.
Do I need a dedicated vector database, or is Postgres enough?
If you already run PostgreSQL and serve under tens of millions of vectors, Postgres with the pgvector extension is usually enough and avoids operating a second system. Add a dedicated vector database when you need billion-scale search, very high throughput, or advanced hybrid and filtering features that pgvector does not cover as efficiently.
What is HNSW and why does it matter for vector search?
HNSW (Hierarchical Navigable Small World) is the most common approximate-nearest-neighbor index used by vector databases. It builds a layered graph that lets queries reach the closest vectors in near-logarithmic time, balancing recall and latency through tunable parameters. It matters because it is what makes searching millions of embeddings fast enough for interactive RAG.
Ready to move from a prototype to a scalable, secure retrieval layer? Get a tailored architecture and cost plan for your vector search stack from KKRF Tech. Book a free consultation and we will help you ship with confidence.
Start Your AI Project →







