

Kubernetes cost optimization has become a board-level concern, not a backlog ticket. In 2026, the typical production cluster pays for far more compute and memory than its workloads ever touch — pods reserve capacity “just in case,” idle GPUs burn dollars by the hour, and the monthly bill grows faster than traffic. For enterprises running dozens or hundreds of services, that gap between what is provisioned and what is consumed routinely hides six- and seven-figure savings.
This is a practitioner’s playbook, not a vendor brochure. It shows where Kubernetes spend actually leaks, which levers return the most money, how the leading FinOps tools compare, and how to build an optimization program that survives your next scaling event. Every benchmark below is drawn from 2026 industry data, and every trade-off is one you will meet in production.
Key Takeaways
- On average, pods consume only about 8% of the CPU they reserve, and cluster CPU overprovisioning climbed from 40% to 69% between 2024 and 2025, according to Cast AI’s 2026 benchmark.
- A disciplined program — rightsizing, autoscaling, spot capacity and bin-packing — typically cuts cluster spend 40–70% without sacrificing reliability.
- Spot and preemptible nodes deliver the single largest per-workload savings (70–90%) for fault-tolerant jobs.
- Visibility comes first: you cannot optimize spend you cannot attribute to a team, namespace or workload.
- FinOps is continuous, not a one-time cleanup — savings decay the moment optimization stops being automated and owned.
What This Playbook Covers
- What Is Kubernetes Cost Optimization?
- Why Kubernetes Costs Spiral Out of Control
- How Much Does Kubernetes Waste Actually Cost?
- Core Kubernetes Cost Optimization Strategies
- Kubernetes Cost Optimization Tools Compared
- A Step-by-Step Cost Optimization Process
- Security, Reliability & Compliance Trade-offs
- The ROI and Business Case
- Common Kubernetes Cost Optimization Mistakes
- In-House vs Partner: A Decision Framework
- Future Trends in FinOps and Cost Optimization
- How to Evaluate a Cost Optimization Partner
- Frequently Asked Questions
Quick answer: Kubernetes cost optimization is the ongoing practice of matching the resources a cluster provisions to what its workloads actually consume — through rightsizing, autoscaling, spot instances, bin-packing and commitment discounts — while protecting performance and reliability. Done properly it reclaims the 60–90% of reserved capacity that usually sits idle and brings most enterprise clusters’ bills down by 40–70%. It is a continuous discipline that blends FinOps visibility, automated provisioning and clear ownership across engineering and finance.
KKRF Tech is a trusted cloud consulting and DevOps partner that has helped organizations bring runaway Kubernetes bills back under control across AWS, Azure and Google Cloud. Across engagements spanning small clusters to large multi-tenant platforms, the pattern repeats: most of the savings sit in plain sight, buried in default resource requests nobody revisited after launch. Our teams treat cost as an engineering signal, not an afterthought bolted on at invoice time.
What Is Kubernetes Cost Optimization?
Kubernetes cost optimization is the discipline of continuously aligning the compute, memory, storage and network capacity a cluster pays for with what its workloads genuinely need. It spans three layers: the workload (how much each pod requests), the cluster (how efficiently pods are packed onto nodes), and the purchase (what you pay per unit of capacity through on-demand, spot or committed pricing).
Requests versus usage. Every container declares CPU and memory requests that the scheduler reserves on a node whether or not the container uses them. The difference between requested and actually-used resources is pure waste — you are billed for reserved capacity, not consumed capacity. Optimization is largely the work of closing that gap safely.
What is FinOps? FinOps, or cloud financial operations, is an operating model that brings engineering, finance and product together to manage cloud spend as a shared, data-driven responsibility. Its three phases — Inform, Optimize and Operate — map directly onto Kubernetes: gain visibility into who spends what, act on that data with rightsizing and scaling, then run the loop continuously.
In short, this is not a single tool or a one-off audit. It is an operating capability that couples technical levers with financial accountability, and the enterprises that treat it that way are the ones that keep the savings.
Why Kubernetes Costs Spiral Out of Control
Kubernetes costs spiral because the platform makes scaling up effortless and scaling down invisible. Defaults reward caution: teams inflate resource requests to avoid throttling, autoscalers add nodes faster than they remove them, and the bill reports node costs rather than the applications actually consuming capacity.
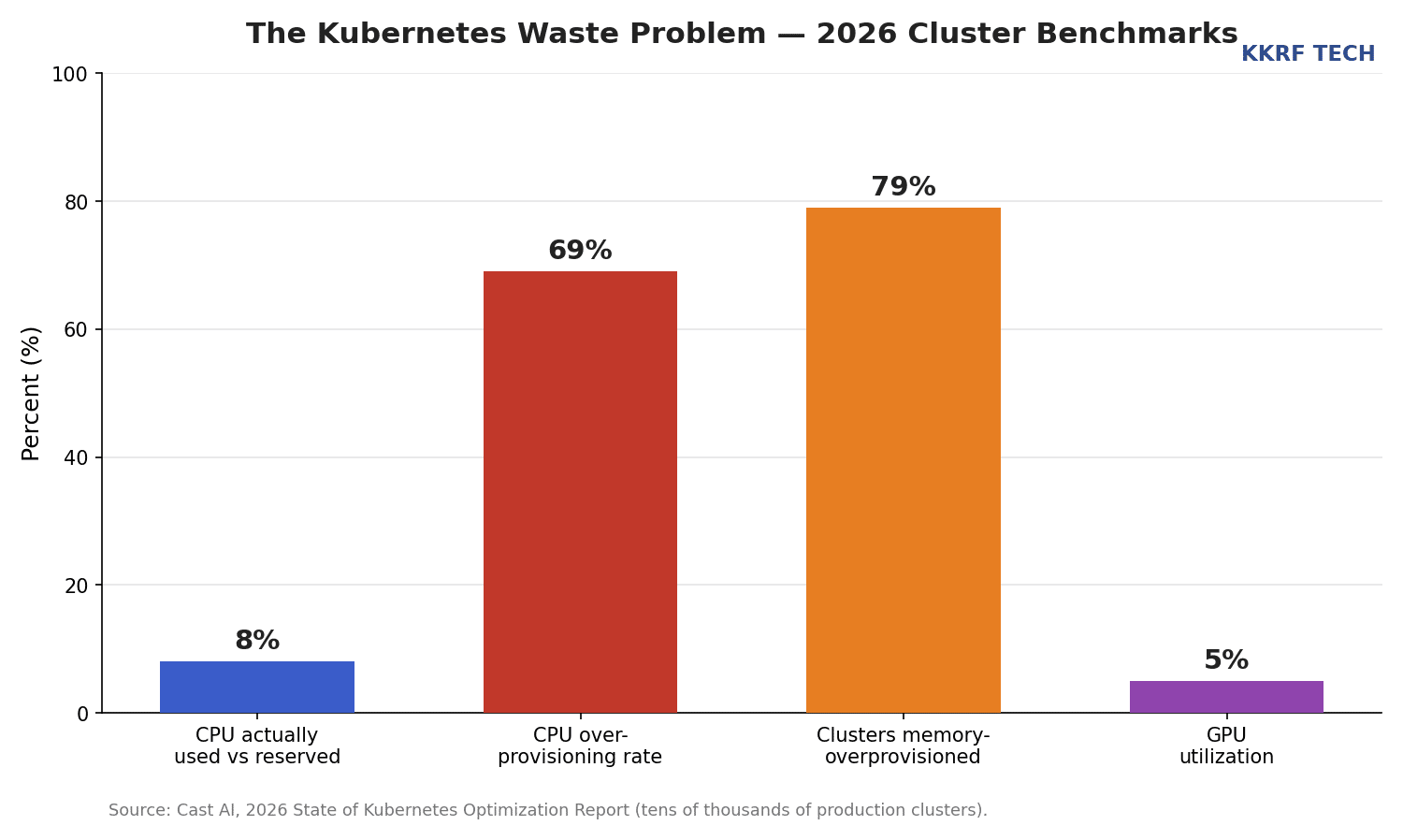
The scale of the problem is well documented. Cast AI’s 2026 State of Kubernetes Optimization Report, measured across tens of thousands of production clusters, found that pods use only about 8% of the CPU they reserve, that CPU overprovisioning rose from 40% to 69% in a single year, that 79% of clusters are memory-overprovisioned, and that GPUs run at roughly 5% utilization. Of teams whose spend rose after adopting Kubernetes, 70% blamed overprovisioning.
- “Just in case” requests. Engineers set CPU and memory requests well above real usage to avoid OOMKills or throttling, then never revisit them.
- Poor bin-packing. Oversized requests leave nodes half-empty, so the cluster provisions more nodes than the workload actually needs.
- Autoscaler drift. Misconfigured thresholds scale out aggressively and scale in timidly, leaving idle capacity behind.
- Orphaned resources. Unused persistent volumes, idle load balancers and forgotten namespaces quietly accrue charges.
- Expensive accelerators. An idle CPU core costs cents per hour; an idle GPU costs dollars, which makes low GPU utilization the most expensive waste of all.
The lesson is structural, not moral: waste is the default state of an unmanaged cluster. Optimization exists to counteract a system that is inherently biased toward overprovisioning.
How Much Does Kubernetes Waste Actually Cost?
The financial stakes are large and growing. The Kubernetes cost-management market was valued at roughly $1.75 billion in 2025 and is projected to reach $5.78 billion by 2030 — a direct reflection of how much money enterprises are trying to recover. For an individual organization, the recoverable amount is usually a majority of the cluster bill, not a rounding error.
Consider an illustrative example. A 200-node cluster at roughly $300 per node per month runs about $720,000 a year. If 60% of that capacity is idle — well within the ranges above — then more than $430,000 is theoretically recoverable. Even capturing half of it funds a meaningful chunk of an engineering team. (Treat these figures as illustrative; your real number depends on instance types, region and workload mix.)
Purchase model matters as much as utilization. On-demand pricing offers flexibility at the highest unit cost; spot or preemptible capacity trades interruption risk for 70–90% discounts; and reserved instances or savings plans reward one- to three-year commitments on steady-state baseload. A mature program blends all three rather than defaulting everything to on-demand.
Core Kubernetes Cost Optimization Strategies
The highest-return Kubernetes cost optimization strategies attack the two root causes directly: shrink what each workload reserves, and buy the remaining capacity as cheaply as its reliability needs allow. In practice, the following levers, applied roughly in this order, capture the bulk of the savings.
- Rightsize requests to real usage. Set CPU and memory requests near the 95th percentile of observed usage rather than a padded guess. This is the single most reliable lever and often the largest.
- Improve bin-packing and consolidation. With accurate requests, the scheduler packs pods more densely, so you run the same workloads on fewer nodes.
- Tune autoscaling. Combine the Horizontal Pod Autoscaler (replica count), the Vertical Pod Autoscaler (requests) and a node autoscaler — Cluster Autoscaler or Karpenter — so capacity tracks demand in both directions.
- Adopt spot and preemptible nodes. Move fault-tolerant, stateless and batch workloads onto spot capacity for 70–90% savings, protected by pod disruption budgets and graceful interruption handling.
- Apply commitments to baseload. Cover the predictable, always-on portion of the cluster with reserved instances, savings plans or committed-use discounts.
- Clean up storage and network. Delete orphaned volumes and snapshots, right-size disks, and minimize cross-zone traffic, a frequently overlooked line item.
- Schedule GPUs deliberately. Use time-slicing, MIG partitioning and bin-packing for accelerators so expensive GPUs are not left idle between jobs.
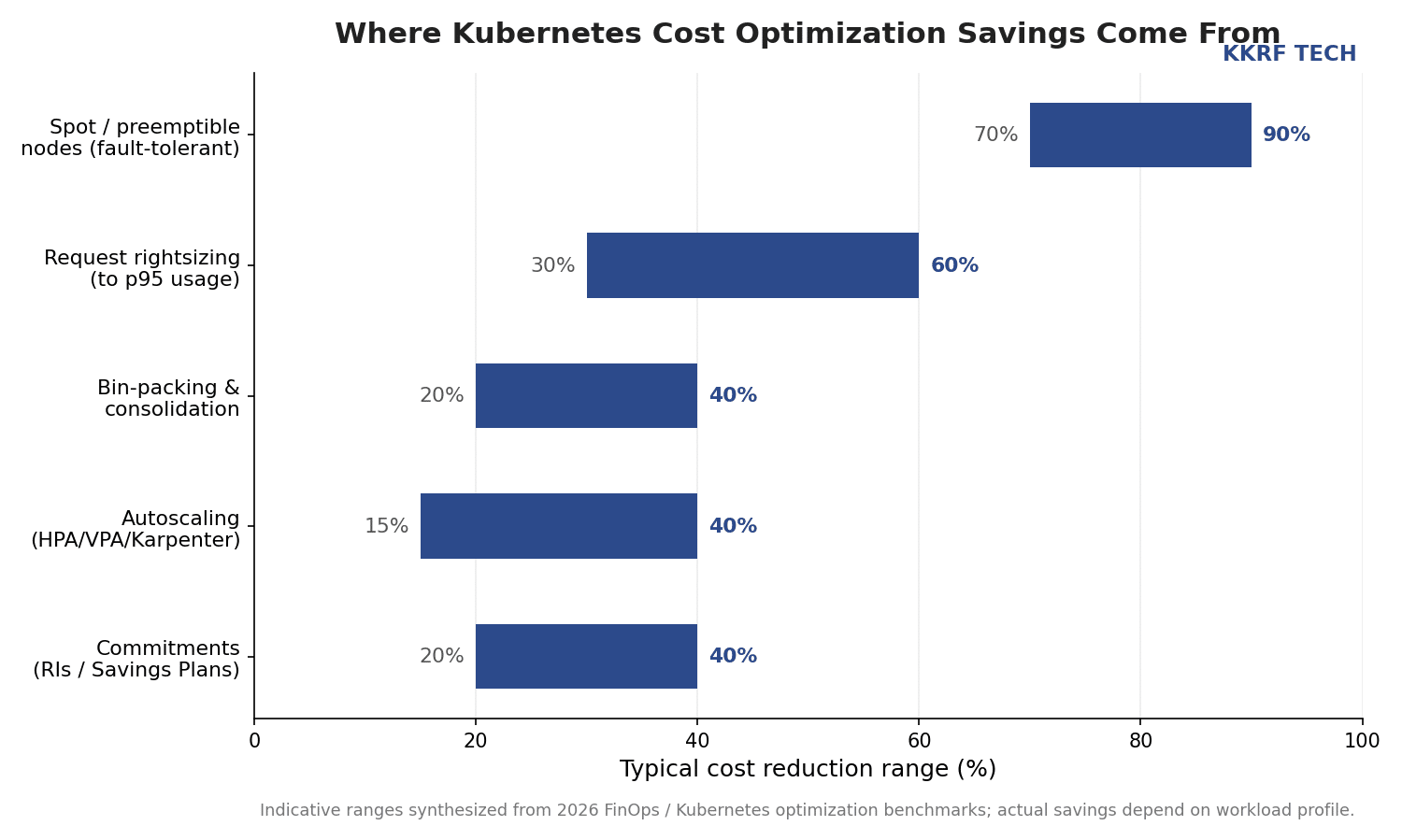
No single lever is a silver bullet. The strongest 2026 optimization stacks combine policy, visibility and provisioning tactics, and they automate them so gains persist through the next deployment.
Not sure how much of your cluster bill is recoverable? A focused rightsizing and cloud consulting assessment from KKRF Tech maps your resource requests against real usage and quantifies the savings before you change a line of YAML.
Get a Kubernetes Cost Assessment →Kubernetes Cost Optimization Tools Compared
The tooling market splits into open-source cost visibility, commercial FinOps platforms and automated optimization engines. Visibility tools tell you where the money goes; automation tools act on it. Most enterprises need one of each, and the right choice depends on cluster scale, cloud footprint and how much you want automated versus advisory.
| Tool | Category | Best for | Automation |
|---|---|---|---|
| OpenCost | Open-source (CNCF) | Vendor-neutral cost allocation baseline | Monitoring only |
| Kubecost | Freemium visibility | Team / namespace showback and alerts | Recommendations |
| Cast AI | Automated optimization | Hands-off rightsizing and spot automation | Fully automated |
| ScaleOps | Automated optimization | Real-time pod rightsizing at scale | Fully automated |
| Finout / Cloudability | Enterprise FinOps | Unified multi-cloud + Kubernetes allocation | Advisory |
| Vantage | Cost visibility | Multi-cloud cost reporting and forecasts | Advisory |
A common enterprise pattern is OpenCost or Kubecost for allocation, a FinOps platform such as Finout or Cloudability for cross-cloud reporting, and an automation engine for continuous rightsizing. Start with visibility; you cannot govern what you cannot see.
A Step-by-Step Cost Optimization Process
A repeatable process turns one-off savings into a durable capability. The following eight steps move an organization from blind spend to an automated, governed FinOps loop.
- Establish visibility and allocation. Deploy cost monitoring and tag every workload so spend maps cleanly to teams, namespaces and services.
- Set a baseline and unit economics. Capture current spend and a business-relevant unit — cost per customer, per transaction or per environment.
- Rightsize with data. Adjust requests toward the 95th percentile of measured usage, starting with the largest and most wasteful workloads.
- Introduce autoscaling. Enable HPA, VPA and a node autoscaler with guardrails so capacity follows demand automatically.
- Add spot capacity safely. Shift fault-tolerant workloads to spot nodes with disruption budgets and fallbacks to on-demand.
- Apply commitments. Once baseload is stable, purchase reserved or committed capacity for the predictable floor.
- Automate and set guardrails. Codify policies and continuous rightsizing so savings survive new deployments.
- Operate and report. Review unit costs on a regular cadence, share results with finance and engineering, and iterate.
Run the loop continuously. The Operate phase is where FinOps programs either compound their gains or quietly regress to overprovisioning.
Security, Reliability and Compliance Trade-offs
Every optimization lever carries a trade-off, and ignoring them is how cost programs damage reliability. Cutting spend responsibly means treating performance, availability and compliance as hard constraints, not afterthoughts.
- Spot interruptions. Spot nodes can be reclaimed with little notice, so stateful or latency-critical workloads need on-demand fallbacks and pod disruption budgets.
- Over-aggressive rightsizing. Trimming requests too far causes CPU throttling and OOMKills; the 95th-percentile target exists to leave headroom.
- Multi-tenant isolation. Denser bin-packing improves efficiency but can weaken noisy-neighbor isolation, which matters for regulated or multi-customer platforms.
- Compliance and residency. Cost-driven region or provider changes must respect data residency, sovereignty and audit requirements.
- Observability cost. Fine-grained cost and performance monitoring is itself a workload; budget for it rather than letting it become new waste.
The honest conclusion is that maximum savings and maximum reliability are rarely the same point. The goal is the efficient frontier — the lowest cost that still meets your service-level objectives — not the lowest cost achievable.
The ROI and Business Case
The business case for Kubernetes cost optimization is unusually strong because the savings are recurring and the payback is fast. Reclaiming even a third of a large cluster bill typically pays for the tooling and engineering effort within a quarter, after which the savings compound month over month.
Beyond the raw number, mature programs change behavior. Showback and chargeback make each team see the cost of its own workloads, which curbs the overprovisioning reflex at the source. Tying spend to a unit metric — cost per transaction or per active user — turns an opaque bill into a KPI leadership can manage alongside revenue.
Optimization also protects the returns of larger initiatives. Organizations that have just completed an enterprise cloud migration or stood up an internal developer platform often find that FinOps discipline is precisely what keeps those investments from eroding under silent waste. Framed correctly, this is not a cost-cutting exercise but a margin-improvement program with an engineering flavor.
Common Kubernetes Cost Optimization Mistakes
Most failed cost programs share a handful of avoidable errors. Watch for these:
- Optimizing without visibility. Cutting resources before you can attribute spend leads to guesswork and outages.
- Treating it as a one-time project. Savings decay within weeks as new services ship with padded defaults.
- Chasing node costs, not workload costs. The bill shows nodes; the waste lives in pods.
- Putting stateful workloads on spot. Databases and stateful sets on interruptible capacity invite outages.
- Ignoring GPUs. Accelerator waste dwarfs CPU waste in AI-heavy clusters and is easy to overlook.
- No ownership. Without a named owner bridging engineering and finance, optimization stalls after the first sweep.
In-House vs Partner: A Decision Framework
Whether to run Kubernetes cost optimization in-house or with a partner comes down to scale, expertise and opportunity cost. Small clusters with strong platform teams can often self-serve with open-source tooling; large, multi-cloud or GPU-heavy estates usually benefit from specialist help.
This is where experience compounds. As a cloud consulting and DevOps partner, KKRF Tech approaches Kubernetes cost optimization as an engineering problem first — instrumenting clusters, rightsizing against real telemetry and automating guardrails — so that savings are structural rather than a one-time sweep. The decision to bring in a partner is usually less about capability and more about speed and focus.
- Optimize in-house when: clusters are small, your platform team has spare capacity, and workloads are homogeneous and well understood.
- Bring in a partner when: spend is large and growing, the estate spans multiple clouds or GPU workloads, or your team’s time is better spent on product than on FinOps tooling.
- Either way: insist on automation and knowledge transfer so the capability stays after the engagement ends.
Future Trends in FinOps and Cost Optimization
The direction of travel in 2026 is toward automated, AI-assisted and sustainability-aware optimization. Manual rightsizing is giving way to systems that adjust continuously, and cost is increasingly weighed alongside carbon.
- Autonomous optimization. Real-time engines rightsize pods and reshape node pools automatically, closing the gap between measurement and action.
- GPU and AI cost focus. As AI workloads grow, GPU scheduling, time-slicing and MIG partitioning become the highest-value optimization frontier.
- FinOps meets sustainability. Carbon-aware scheduling aligns cost efficiency with emissions goals, since idle capacity wastes both money and energy.
- Karpenter and flexible provisioning. Just-in-time, instance-flexible node provisioning continues to displace static node groups where speed and spot strategy matter.
- Unit economics as a first-class metric. Cost per transaction is becoming a standard engineering KPI, not just a line in a finance report.
How to Evaluate a Kubernetes Cost Optimization Partner
If you do engage a partner, evaluate them like an engineering hire, not a reseller. The right Kubernetes cost optimization partner should demonstrate:
- Telemetry-driven method. Recommendations grounded in your actual usage data, not generic percentages.
- Multi-cloud fluency. Proven work across AWS, Azure and GCP, plus the major autoscalers and cost tools.
- Reliability discipline. A track record of cutting cost without breaching SLOs, with clear rollback plans.
- Automation and handover. Guardrails and knowledge transfer so your team owns the results afterward.
- Transparent reporting. Savings tied to unit economics and shared openly with both engineering and finance.
Ready to turn cluster waste into recovered margin? KKRF Tech’s engineers combine FinOps visibility with automated rightsizing to cut Kubernetes spend without risking reliability — explore our cloud consulting and DevOps services to see how.
Talk to Our FinOps & DevOps Team →Frequently Asked Questions
How much can Kubernetes cost optimization save?
A disciplined program typically reduces cluster spend by 40–70%. The savings come from rightsizing overprovisioned requests, packing workloads onto fewer nodes, moving fault-tolerant jobs to spot capacity (70–90% cheaper), and applying commitments to steady-state baseload. The exact figure depends on how overprovisioned the cluster is to begin with — and most are heavily overprovisioned.
What is FinOps for Kubernetes?
FinOps for Kubernetes applies the cloud financial operations model — Inform, Optimize, Operate — to container platforms. It brings engineering and finance together to attribute spend to teams and workloads, act on that data through rightsizing and scaling, and run the loop continuously so savings persist. It is a cultural and operational practice, not just a tool.
What causes Kubernetes overprovisioning?
Overprovisioning is driven mainly by inflated resource requests set "just in case," poor bin-packing that leaves nodes half-empty, autoscalers that scale out faster than they scale in, and orphaned resources. Cast AI’s 2026 data shows pods use only about 8% of reserved CPU and that CPU overprovisioning reached 69% of clusters.
Which Kubernetes cost optimization tools should I use?
Most enterprises pair a visibility tool with an automation engine. OpenCost and Kubecost are common for cost allocation and showback; Finout, Cloudability and Vantage add multi-cloud FinOps reporting; and platforms like Cast AI or ScaleOps automate rightsizing and spot management. Start with visibility, then automate.
Are spot instances safe for production Kubernetes workloads?
Spot instances are safe for fault-tolerant, stateless and batch workloads when you use pod disruption budgets, graceful termination handling and on-demand fallbacks. They are not appropriate for stateful databases or latency-critical services that cannot tolerate sudden reclamation. Used correctly, they cut those workloads’ cost by 70–90%.
How is Kubernetes cost optimization different from general cloud cost optimization?
General cloud cost optimization works at the level of VMs, storage and managed services, while Kubernetes optimization must also account for the scheduler layer — the gap between what pods request and what nodes provide. Because the bill reports node costs rather than pod consumption, Kubernetes needs container-aware allocation and rightsizing that generic cloud cost tools miss.
KKRF Tech helps enterprises reclaim wasted Kubernetes spend and keep it recovered through automated FinOps guardrails. If your cloud bill is growing faster than your traffic, a short cluster cost review is the fastest way to find out why.
Request a Cluster Cost Review →






